A/ Spark
I/ Architecture vocabulary
| Component | Desc |
|---|---|
| cluster node | is composed of several worker nodes |
| worker node | launches 1 or several executors & is dedicated exclusively to its parent application |
| executor | is a java application & may start several threads |
| executor’s thread | runs several job’s tasks sequentially |
| applications | runs several spark jobs & launches 1 worker by cluster node |
| job | is a collection of stages organized in DAG |
| stage | is a DAG of steps whose roots and leafs are shuffles or I/Os |
| step | runs as a collection of tasks |
| task | operate on 1 RDD’s partition |
DAG = Directed Acyclic Graph. They are used by spark to represent Jobs’ stages or Stages’ steps
II/ APIs
Although the term Application Programming Interface is mostly used for the element exposing the services of a web server, it has a more general meaning.
For frameworks as extended as Spark, it names specific ways of interacting with the library available for the user.
Spark features different APIs with different purposes, which serve as front-facing interfaces masking more complex underlying or structural code (Facade Pattern): Even if every spark job runs RDD-based pipelines, Spark offers different ways to construct a job:
- Core API (Spark Core): user manipulates directly the RDDs, it is the low level API
- Dataset API (Spark SQL): User manipulates high level typed objects
- DataFrame API (Spark SQL): User manipulates high level untyped objects
- SQL API (Spark SQL): User writes SQL query strings
(3 last APIs leverage a descriptive programming model and the structuration of the manipulated data to produce optimized Spark jobs)
Note: By convention, when talking about Dataset API, we talk about manipulation of Dataset[T] objects with T different from Row. The manipulation of Dataset[Row] objects is called DataFrame API (as DataFrame is a type alias for Dataset[Row]).
III/ Unified Memory Management (1.6+)
Useful sources:
- pull request document Unified Memory Management in Spark 1.6 by Andrew Or and Josh Rosen
- blog article Apache Spark and off-heap memory by Bartosz Konieczny.
- blog article Deep Understanding of Spark Memory Management Model by Alex
-
blog article [How does Facebook tune Apache Spark for Large-Scale Workloads?](https://towardsdatascience.com/how-does-facebook-tune-apache-spark-for-large-scale-workloads-3238ddda0830Spark SQL’s Datasets & DataFrames
- Spark SQL first realease: Spark 1.0.0 (May 30, 2014) (see Spark SQL’s paper by Michael Armbrust)
- Tuning Spark doc
1) Allocation of the memory of a worker W to a given executor E
TODO: fix links text length cut
off-heap overhead space for E:
-VM overheads
-interned strings
-other native overheads] -2[... for other on-heap memory or
off-heap overhead of W's executors] 2[off-heap space shared
among W's executors] 33[off-heap execution
region for W's executors] 44[off-heap storage
region for W's executors] -4[on-heap memory for E] 10[Reserved Memory for Spark internal objects] 0[on-heap execution & storage
region for E] 3[on-heap execution
region for E] 4[on-heap storage
region for E] 5[User Memory for E:
-on-heap internal metadata
-user data structures
-handling of miss-estimated
unusually large records] -4 --"300MB"--> 10 -1 --> -2 -1 --"spark.memory.offHeap.size
(in bytes, default=0)"-->2 -1--"spark.executor.memory
(JVM string format, default=''1g'')"-->-4 -1 --"spark.executor.memoryOverhead
(in MiB, default=max(driverMemory * 0.10, 384)"-->-3 -4 --"(... - 300MB) * spark.memory.fraction
(spark.memory.fraction default=0.6)"-->0 -4 --"(... - 300MB) * (1-spark.memory.fraction)
(1- spark.memory.fraction default=0.4)"-->5 0 --"... * spark.memory.storageFraction
(spark.memory.storageFractiondefault=0.5)"--> 4 0 --"... * (1 - spark.memory.storageFraction)
(1 - spark.memory.storageFraction default=0.5)"--> 3 2 --"... * spark.memory.storageFraction
(spark.memory.storageFraction default=0.5)"--> 44 2 --"... * (1 - spark.memory.storageFraction)
(1 - spark.memory.storageFraction default=0.5)"--> 33
Special case of client mode
In client mode the driver process is a thread created inside the spark app JVM. So in order to set spark.driver.memory for example, one have to do it through spark-submit option --driver-memory and setting it through SparkConf in the application will have no effect.
In local mode
Similarly to client mode, in local mode the driver process runs inside the spark app JVM and its memory allocations have to be passed before its start (spark-submit, Xmx). The (single) executor process lives inside the spark app JVM too and face its restrictions.
2) On-heap executor space
The On-heap executor space is divided in 2 regions:
- Execution region: buffering intermediate data when performing shuffles, joins, sorts and aggregations
Note about OOMs and execution region: Operators like join or sort produce data structures (arrays, maps, see for example org.apache.spark.sql.execution.UnsafeExternalRowSorter) that are optimized but grow with partitions size (in bytes or in records). Thus it is recommended to use a partitioning that split the data in chunks of a size that fits in $\frac{executionRegionSize}{spark.executor.cores}$. This is an order of magnitude but some operators are more greedy than others and only experience/experiments can help to tune memory settings fine to avoid throwing away money with unused resources.
- Storage region:
- caching data blocks to optimize for future accesses
- torrent broadcasts
- sending large task results
3) Execution and storage regions behaviors in unified memory management
- if execution needs to use some space:
- if its region space is not filled: it uses it
- else if there is available unused space in storage region: it borrows it and uses it
- else if some of its region space has been borrowed by storage: it takes it back by evicting some blocks (simply removed if
MEMORY_ONLYbut spilled to disk ifMEMORY_AND_DISK) - else: excess data is spilled to disk and it uses freed space
- if storage needs to use some space (i.e. storage level of a data needed to be cached starts with
MEMORY_):- if its region space is not filled: it uses it
- else if there is available unused space in execution region: it borrows it and uses it
- else if some of its region space has been borrowed by execution, it will try (may not be possible due to implementation complexities) to take it back and use it.
- else: excess cached blocks are evicted
Notes on block eviction:
- When a cached RDD blocks is evicted from storage region, it means that it is simply removed if
MEMORY_ONLYbut spilled to disk ifMEMORY_AND_DISK. - The choice of the next block to evict follows a Least Recently Used policy.
- A block of an RDD cannot be evicted to put another block of the same RDD.
IV/ Memory format (during processing) evolution (SQL)
sources:
- https://spoddutur.github.io/spark-notes/deep_dive_into_storage_formats.html ___
- 1.0.0 (May 26, 2014): There was no “DataFrame” but only
SchemaRDD. It was aRDDof fully deserialized Java Objects. - 1.3.0 (Mar 6, 2015)Memory format
1) Rows format evolution
https://spoddutur.github.io/spark-notes/deep_dive_into_storage_formats.html
- 1.0.0: There was no “DataFrame” but only
SchemaRDD. It was aRDDof Java Objects on-heap (see spark Spark’s RDDs paper by Matei Zaharia, 2011). - 1.3.0:
DataFrameis born and is still and RDD of deserializedon-heap objects.SchemaRDDbecame an alias for smooth deprecation purpose.
@deprecated("use DataFrame", "1.3.0")
type SchemaRDD = DataFrame
- Since 1.4.0 (June 11, 2015) it is
RDDofInternalRows that are almost always implemented asUnsafeRows. They:- are Binary Row-Based Format known as Tungsten Row Format, that stores values in one bytes array instead of Java objects:

- allows in-place elements access that avoid expensive Java/Kryo serialization/deserialization. This format is a a bit slower compared to access to elements from an
RDDof Java objects cached in memory but much faster when it comes to shuffles. Shuffle is also improved thanks to the tinier memory footprint of the row, leading to saves in network bandwidth.
-
Leverage the activation of the off-heap memory usage more than RDDs of deserialized objects by not implying ser/deser overhead.
- have GC benefits because they imply less long living references to be created: for example if a String need to be manipulated, characters will be in-place accessed in binary format and the String life is only 1 row processing duration -> these short life time ensure that they are always in the “young” set of references for garbage collection. (see “Advanced GC Tuning” section)
- are Binary Row-Based Format known as Tungsten Row Format, that stores values in one bytes array instead of Java objects:
- 1.6.0 (Dec 22, 2015):
Datasetis created as a separated class. There is conversions betweenDatasets andDataFrames. - Since 2.0.0 (Jul 19, 2016),
DataFrameis merged withDatasetand remains just an aliastype DataFrame = Dataset[Row].
2) contoguousity (TODO validate) (SQL)
There is only a contiguousity of the UnsafeRows’ memory because an RDD[UnsafeRow] is a collection of UnsafeRows’ referencies that lives somewhere on-heap. This causes many CPU’s caches defaults, each new record to process causing one new default.
3) Caching (SQL)
| default storage level | |
|---|---|
RDD.persist |
MEMORY_ONLY |
Dataset.persist |
MEMORY_AND_DISK |
- When a dataset is cached using
def cache(): this.type = persist()it is basicallypersisted with defaultstorageLevelwhich isMEMORY_AND_DISK:
/**
* Persist this Dataset with the default storage level (`MEMORY_AND_DISK`).
*
* @group basic
* @since 1.6.0
*/
def persist(): this.type = {
sparkSession.sharedState.cacheManager.cacheQuery(this)
this
}
/**
* Persist this Dataset with the default storage level (`MEMORY_AND_DISK`).
*
* @group basic
* @since 1.6.0
*/
def cache(): this.type = persist()
sparkSession.sharedState.cacheManager.cacheQuerystores plan and other information of the df to cache in anIndexedSeqof instances of:
/** Holds a cached logical plan and its data */
case class CachedData(plan: LogicalPlan, cachedRepresentation: InMemoryRelation)
-
InMemoryRelationholds a memory optimizedRDD[CachedBatch]whose memory format is columnar and optionally compressed. -
Caching is shared among
LogicalPlans with same result, inCacheManager:
def lookupCachedData(plan: LogicalPlan): Option[CachedData] = readLock {
cachedData.asScala.find(cd => plan.sameResult(cd.plan))
}
-
unpersist()is not lazy, it directly remove the dataframe cached data. -
Caching operations are not purely functional:
df2 = df.cache()
is equivalent to
df.cache()
df2 = df
- cached blocks are not replicated by default, neither in memory nor when spilled (which stores on disks using local file system). You can activate a factor 2 replication by appending a
_2suffix to any storage level constant, for exampleMEMORY_AND_DISK_2.
4) How to know if a particular DataFrame is sorted ?
One can use df.queryExecution.sparkPlan.outputOrdering that returns a sequence of org.apache.spark.sql.catalyst.expressions.SortOrders to retrieve this information:
def isSorted(df: Dataset[_]): Boolean =
.
```scala
val dfIsSorted = !df.sort().queryExecution.sparkPlan.outputOrdering.isEmpty
V/ DataFrame vs other Dataset[<not Row>] steps of rows processing steps
Short: DataFrame less secure but a little bit more performant regarding GC pressure.
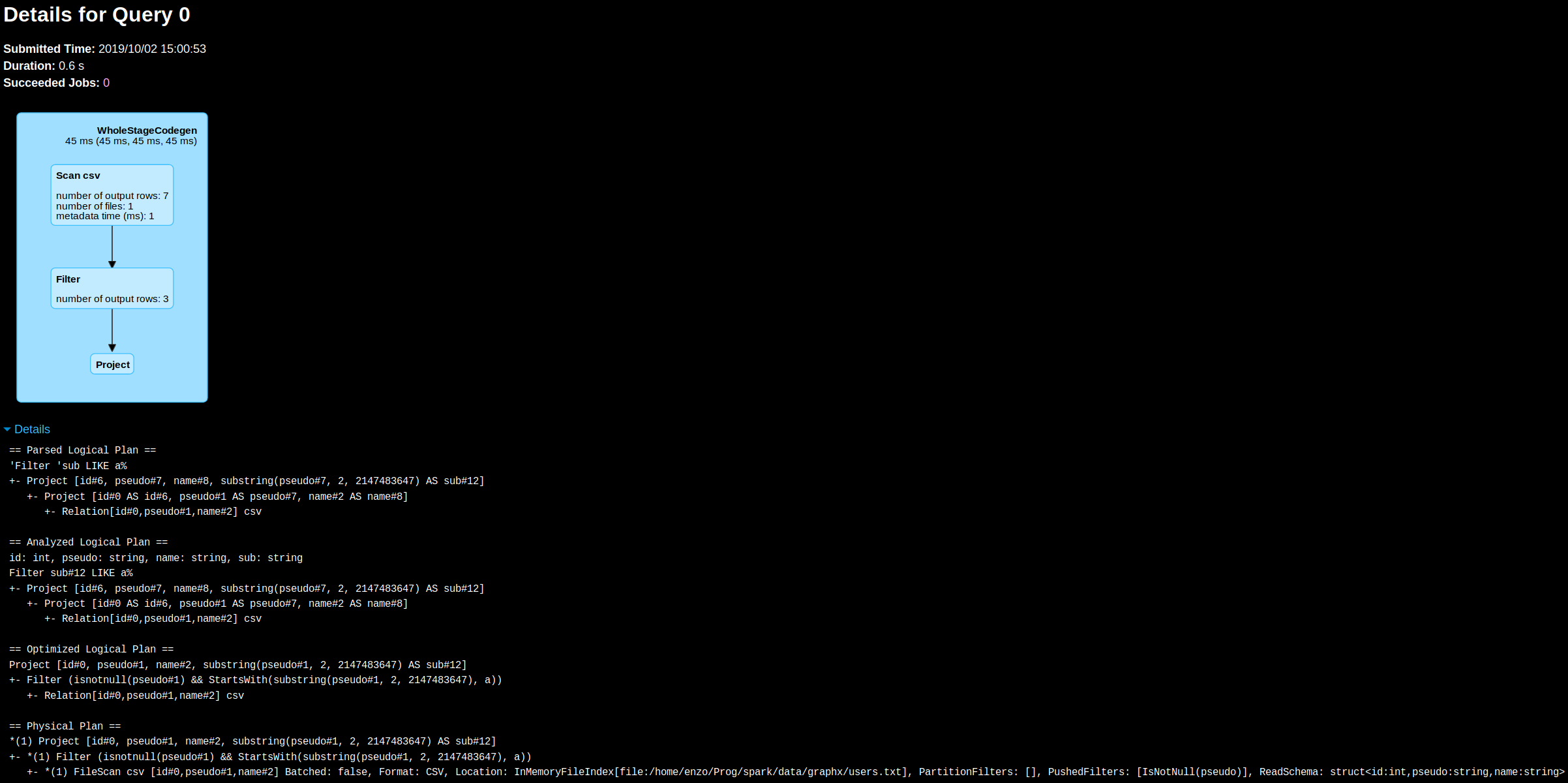
Let’s compare processing steps of the GeneratedIteratorForCodegenStage1 class that you can view by calling .queryExecution.debug.codegen() on a DataFrame
The semantic is:
- load a csv with three column: an Integer id, a String pseudo and a String name.
- create a new feature containing a substring of the pseudo
- apply a filter on the new feature
1) DataFrame’s WholeStageCodegen execution …
val df = spark.read
.format("csv")
.option("header", "false")
.option("delimiter", ",")
.schema(StructType(Seq(
StructField("id", IntegerType, true),
StructField("pseudo", StringType, true),
StructField("name", StringType, true))))
.load("/bla/bla/bla.csv")
.toDF("id", "pseudo", "name")
.selectExpr("*", "substr(pseudo, 2) AS sub")
.filter("sub LIKE 'a%' ")
{kind=link}
Steps (~80 lines of generated code):
- Get input
Iteratorduring init:public void init(int index, scala.collection.Iterator[] inputs). AnUnsafeRowWriteris also instanciated with 4 fields:
filter_mutableStateArray_0[1] = new org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter(4, 96)
protected void processNext()method is used to launch processing. It iterates through the input iterator, casting each element into anInternalRow.
InternalRow scan_row_0 = (InternalRow) scan_mutableStateArray_0[0].next();
- It instanciates Java objects from the needed fields. There is no expensive deserialization thanks to
UnsafeRowin-place accessors implementation. Here it gets pseudo:
boolean scan_isNull_1 = scan_row_0.isNullAt(1);
UTF8String scan_value_1 = scan_isNull_1 ? null : (scan_row_0.getUTF8String(1));
- If the pseudo column is not null, it computes the new feature using substring
if (!(!scan_isNull_1)) continue;
UTF8String filter_value_3 = scan_value_1.substringSQL(2, 2147483647);
- Apply the filter with a direct call to
.startsWithand if the result is negative, it skips the current record.referencesis anObject[]that holds udfs, and constants parameterizing the processing.references[2]holds the string"a".
// references[2] holds the string "a"
boolean filter_value_2 = filter_value_3.startsWith(((UTF8String) references[2]));
if (!filter_value_2) continue;
- Even if the new feature has already been computed for filtering purpose, it is computed another time for the new column itself. The other needed fields for output (id and name) are scanned.
boolean scan_isNull_0 = scan_row_0.isNullAt(0);
int scan_value_0 = scan_isNull_0 ? -1 : (scan_row_0.getInt(0));
boolean scan_isNull_2 = scan_row_0.isNullAt(2);
UTF8String scan_value_2 = scan_isNull_2 ? null : (scan_row_0.getUTF8String(2));
UTF8String project_value_3 = null;
project_value_3 = scan_value_1.substringSQL(2, 2147483647);
- The final fields are written with the pattern:
if (false) {
filter_mutableStateArray_0[1].setNullAt(3);
} else {
filter_mutableStateArray_0[1].write(3, project_value_3);
}
- The
UnsafeRowis builded and appended to aLinkedList<InternalRow>(attribute defined in the subclassBufferedRowIterator)
append((filter_mutableStateArray_0[1].getRow()));
2) … vs Dataset’s WholeStageCodegen execution
val ds = spark.read
.format("csv")
.option("header", "false")
.option("delimiter", ",")
.schema(StructType(Seq(
StructField("id", IntegerType, true),
StructField("pseudo", StringType, true),
StructField("name", StringType, true))))
.load("/home/enzo/Data/sofia-air-quality-dataset/2019-05_bme280sof.csv")
.toDF("id", "pseudo", "name")
.as[User]
.map((user: User) => if(user.name != null)(user.id, user.name, user.pseudo, user.name.substring(1)) else (user.id, user.name, user.pseudo, ""))
.filter((extendedUser: (Int, String, String, String)) => extendedUser._4.startsWith("a"))
{kind=link}
Steps (~300 lines of generated code):
- Get input
Iteratorduring init:public void init(int index, scala.collection.Iterator[] inputs). AnUnsafeRowWriteris also instanciated with 4 fields:
project_mutableStateArray_0[1] = new org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter(4, 96)
protected void processNext()method is used to launch processing. It iterates through the input iterator, casting each element into anInternalRow.
InternalRow scan_row_0 = (InternalRow) scan_mutableStateArray_0[0].next();
- It instanciates Java objects from the needed fields. There is no expensive deserialization thanks to
UnsafeRowin-place accessors implementation. Here it gets pseudo:
boolean scan_isNull_1 = scan_row_0.isNullAt(1);
UTF8String scan_value_1 = scan_isNull_1 ? null : (scan_row_0.getUTF8String(1));
- It passes all the scanned fields to
deserializetoobject_doConsume_0(<fieldX type> fieldXName, boolean fieldXIsNull, ...). This method will build aUser(id: Int, pseudo: String, name: String)instance. In our case it requires to convert the scanned values fromUTF8Strings toString, the cast betweenintandIntbeing automatic.
[...]
deserializetoobject_funcResult_1 = deserializetoobject_expr_2_0.toString();
[...]
final com.bonnalenzo.sparkscalaexpe.playground.User deserializetoobject_value_3 = false ?
null :
new com.bonnalenzo.sparkscalaexpe.playground.User(
deserializetoobject_argValue_0,
deserializetoobject_mutableStateArray_0[0],
deserializetoobject_mutableStateArray_0[1]
);
-
It now calls
mapelements_doConsume_0(deserializetoobject_value_3, false);,deserializetoobject_value_3being theUserinstance lately build. -
mapelements_doConsume_0(com.bonnalenzo.sparkscalaexpe.playground.User mapelements_expr_0_0, boolean mapelements_exprIsNull_0_0)applies the anonymous function provided to themap: apply the substring and return a Tuple4
mapelements_funcResult_0 = ((scala.Function1) references[2]).apply(mapelements_mutableStateArray_0[0]);
if (mapelements_funcResult_0 != null) {
mapelements_value_1 = (scala.Tuple4) mapelements_funcResult_0;
} else {
mapelements_isNull_1 = true;
}
- It also apply the filter and continues to next record if condition not met
filter_funcResult_0 = ((scala.Function1) references[4]).apply(filter_mutableStateArray_0[0]);
if (filter_funcResult_0 != null) {
filter_value_0 = (Boolean) filter_funcResult_0;
} else {
filter_isNull_0 = true;
}
[...]
if (filter_isNull_0 || !filter_value_0) continue;
- It then call
serializefromobject_doConsume_0(mapelements_value_1, mapelements_isNull_1)that will do the necessary conversions (back fromUTF8StringtoDtring…) to build anUnsafeRowfrom theTuple4[Int, String, String, String]usingUnsafeRowWriter.
boolean serializefromobject_isNull_12 = serializefromobject_resultIsNull_2;
UTF8String serializefromobject_value_12 = null;
if (!serializefromobject_resultIsNull_2) {
serializefromobject_value_12 = org.apache.spark.unsafe.types.UTF8String.fromString(deserializetoobject_mutableStateArray_0[4]);
}
[...]
if (serializefromobject_isNull_12) {
project_mutableStateArray_0[7].setNullAt(3);
} else {
project_mutableStateArray_0[7].write(3, serializefromobject_value_12);
}
append((project_mutableStateArray_0[7].getRow()));
3) Additionnal notes
If the only references manipulated using strongly typed Datasets are instances of AnyVal, then it will be as GC friendly as “DataFrame” operations and may only imply a few more method calls. You may want to run these code snippets to verify this:
val ds: Dataset[Double] = spark
.range(n)
.select($"id".as[Long])
.map(id => java.lang.Math.sqrt(id))
ds.queryExecution.debug.codegen()
val df: DataFrame = spark
.range(n)
.select(sqrt(col("id")))
df.queryExecution.debug.codegen()
VI/ Conversion to RDD: df.rdd vs df.queryExecution.toRdd()
.rddIt deserializesInternalRows. It’s still lazy: the need of deserialization is recorded (amapPartitionstransformation is used) but not triggered. It’s a transformation that returnsRDD[T]. If it’s called on aDataFrame = Dataset[Row], it returnsRDD[Row].class Dataset[T] private[sql]( @transient val sparkSession: SparkSession, @DeveloperApi @Unstable @transient val queryExecution: QueryExecution, encoder: Encoder[T]) extends Serializable{ [...] lazy val rdd: RDD[T] = { val objectType = exprEnc.deserializer.dataType rddQueryExecution.toRdd.mapPartitions { rows => rows.map(_.get(0, objectType).asInstanceOf[T]) } }usage:
df.rdd .map((row: Row) => Row.fromSeq(Seq(row.getAs[Long]("i")+10, row.getAs[Long]("i")-10))) .collect().queryExecution.toRdd()
It is used by .rdd.
If you stuck to this step, you keep your rows InternalRows.
class QueryExecution(
val sparkSession: SparkSession,
val logical: LogicalPlan,
val tracker: QueryPlanningTracker = new QueryPlanningTracker) {
[...]
lazy val toRdd: RDD[InternalRow] = executedPlan.execute()
usage:
df.queryExecution.toRdd
.map((row: InternalRow) => InternalRow.fromSeq(Seq(row.getLong(0)+10, row.getLong(0)-10)))
Construct a DataFrame from a RDD[InternalRow] and a schema
def createDataFrameOfInternalRows(internalRows: RDD[InternalRow],
schema: StructType)
(implicit spark: SparkSession): DataFrame =
Dataset.ofRows(spark, LogicalRDD(schema.toAttributes, internalRows)(spark))
Note: Has to be inside package org.apache.spark.sql to have access to private[sql] object Dataset.
VII/ Dataset’s OOP design
Dataset can be viewed as a functional builder for a LogicalPlan, implemented as a fluent API friendly to SQL users.
val df2 = df1.join(...).select(...).where(...).orderBy(...).show()
Dataset class makes use of Delegation Pattern in many places, to delegate work to its underlying RDD, e.g. Dataset.reduce :
def reduce(func: (T, T) => T): T = withNewRDDExecutionId {
rdd.reduce(func)
}
VIII/ SQL window function syntax
(not Spark specific)
SELECT
some_col,
__func__ OVER (
PARTITION BY partitionCol
ORDER BY orderCol __frame_type__
BETWEEN start AND end
)
FROM ...
__func__: Raking/Analytic/Aggregation function
__frame_type__:
- ROW (start and end are then index and offsets:
ROWS BETWEEN UNBOUNDED PRECEDING AND 10 FOLLOWING, the frame contains every records from the begining of the partition to the ten next records after current one) - RANGE (start and end are then values in orderCol unit :
RANGE BETWEEN 13000 PRECEDING AND CURRENT ROW, given that ORDER BY has been performed on column price and that current_p is the price of the current record, the frame contains all the records that have a value of price p that is between current_p -13000 and current_p)
IX/ Vector Type
org.apache.spark.ml.linalg.Vector
has the following spark sql type (note that values are in ArrayType):
private[this] val _sqlType = {
// type: 0 = sparse, 1 = dense
// We only use "values" for dense vectors, and "size", "indices", and "values" for sparse
// vectors. The "values" field is nullable because we might want to add binary vectors later,
// which uses "size" and "indices", but not "values".
StructType(Seq(
StructField("type", ByteType, nullable = false),
StructField("size", IntegerType, nullable = true),
StructField("indices", ArrayType(IntegerType, containsNull = false), nullable = true),
StructField("values", ArrayType(DoubleType, containsNull = false), nullable = true)))
}
X/ Closures
The following will compile and run fine but it will only do what is expected if you run Spark in local mode:
val rdd: RDD[String] = ???
val startingWithA = mutable.Set[String]()
rdd.foreach((a: String) => if (a.toLowerCase().startsWith("a")) startingWithA += a)
println(s"rdd contains ${startingWithA.size} records starting with 'a'")
because startingWithA will not be shared among JVMs in cluster mode.
Actually in non local modes (both client and master), it will print rdd contains 0 records starting with 'a' because the mutable.Set[String]() instance called for its size information lives inside the driver process JVM heap and is not populated by executors threads that live in other JVMs (the executors ones).
Use accumulators instead.
XI/ Include a dependency from spark-package in maven’s pom.xml
- add the repository
- ```xml
## XIII/ Vector Type
`org.apache.spark.ml.linalg.Vector`
has the following spark sql type (note that values are in `ArrayType`):
```scala
private[this] val _sqlType = {
// type: 0 = sparse, 1 = dense
// We only use "values" for dense vectors, and "size", "indices", and "values" for sparse
// vectors. The "values" field is nullable because we might want to add binary vectors later,
// which uses "size" and "indices", but not "values".
StructType(Seq(
StructField("type", ByteType, nullable = false),
StructField("size", IntegerType, nullable = true),
StructField("indices", ArrayType(IntegerType, containsNull = false), nullable = true),
StructField("values", ArrayType(DoubleType, containsNull = false), nullable = true)))
}
XIV/ Partitions in Spark
1) Partitioning (SQL & Core)
a) Partitioner
SQL: Main partitioning
-
HashPartitioning: onkeysuses Murmur Hash 3 (fast non-cryptographic hashing, easy to reverse) (whilePairRDDs ‘partitionBy(hashPartitioner)uses.hashCode()) -
RangePartitioning: Estimate key ditribution with sampling -> find split values -> each partition is splitted according -> result in new partitioning quite even and with no overlapping -
RoundRobinPartitioning: distribute evenly (based on a circular distribution of a quantum/batch of row to each partition). Used whenrepartition(n).
Always partition on Long or Int, hash/encrypt string key if necessary.
b) Materialize partitions into cache
Materializing a rdd: RDD[T] = [...].cache() into cache can be done in two roughly equivalent ways, the first one being less verbose:
rdd.count()rdd.foreachPartition(_ => ())
Materializing a ds: Dataset[T] = [...].cache() into cache can be done in two roughly equivalent ways, the first one being less verbose:
rdd.count()rdd.queryExecution.toRdd.foreachPartition(_ => ())
As it adds two additionnal steps (DeserializeToObjects and MapPartitions), one must avoid to do ds.foreachPartition(_ => ()) which is like doing ds.rdd.foreachPartition(_ => ()), in Dataset.scala:
def foreachPartition(f: Iterator[T] => Unit): Unit = withNewRDDExecutionId(rdd.foreachPartition(f))
As a note, here is what is done inside Spark itself when an eager checkpoint is requested (synchronous/blocking checkpoint), in Dataset.scala:
private def checkpoint(eager: Boolean, reliableCheckpoint: Boolean): Dataset[T] = {
val internalRdd = queryExecution.toRdd.map(_.copy())
if (reliableCheckpoint) {
internalRdd.checkpoint()
} else {
internalRdd.localCheckpoint()
}
if (eager) {
internalRdd.count()
}
Why caching before checkpoint ?
It is encouraged in RDD.scala:
* [...] It is strongly recommended that this RDD is persisted in
* memory, otherwise saving it on a file will require recomputation.
*/
def checkpoint(): Unit = RDDCheckpointData.synchronized {
This is to prevent the RDD’s DAG to be computed twice because in ReliableRDDCheckpointData.scala:
/**
* Materialize this RDD and write its content to a reliable DFS.
* This is called immediately after the first action invoked on this RDD has completed.
*/
protected override def doCheckpoint(): CheckpointRDD[T] = {
c) spark.default.parallelism vs spark.sql.shuffle.partitions
| conf | affects | default |
|---|---|---|
spark.default.parallelism |
Spark core’s join, reduceByKey, parallelize, Spark SQL’s range |
Largest partition number of parents RDDs for join, reduceByKey… and number of available cores for parallelize |
spark.sql.shuffle.partitions |
Spark SQL number of partitions after exchanges (Spark SQL’s shuffles) | 200 |
2) Repartitioning (SQL & Core)
a) coalesce
Make its stage’s tasks work on the union of several collocated partitions: It is a fast way to reduce the number of partitions but that can lead to uneven partitioning.
b) repartition
If column not given: round robin else: hashpartitioning
if numpartition not given: reads "spark.sql.shuffle.partitions"
c) repartitionByRange
repartition by range, forced to pass columns.
d) N°partitions heuristic
Really optimized runtime with n°partitions (= number max of parallel tasks) = 4 or 5 times n°available threads
val spark = SparkSession
.builder
.config("spark.default.parallelism", (<n°CPUs> * 4).toString) // RDDs
.config("spark.sql.shuffle.partitions", <n°CPUs> * 4) // Datasets
[...]
.getOrCreate
3) Pushing the repartitioning to HDFS source
sc.textFile("hdfs://.../file.txt", x)
can lead to a faster execution than
sc.textFile("hdfs://.../file.txt").repartition(x)
because the former will delegate the repartitioning to Hadoop’s TextInputFormat.
4) DataFrameWriters’ partitioning
DataFrameWriter.partitionBy(colNames: String*) allows you to partition job output on the file system. For example this
adults
.write
.format("parquet")
.partitionBy("age", "lastname")
.save("/path/adults.parquet")
repartitions data with key (age, lastname) and will write files using a folder structure like:
/18/jean/
/18/jiovani/
...
/50/giselle/
TODO: Number of splits <!– #### Number of splits
- keeping the last
adultDataFrame as an example and givennits number of partitions - given
gcd(a, b)a function taking two integers and returning their Greatest Common Divisor. - noting
n_confthe value set in"spark.sql.shuffle.partitions"
-> Then each leaf folder of the folder structure (e.g. /18/jean/) will contain x file splits, with:
val x = if (gcd(n_conf, n) != 1) gcd(n_conf, n) else n
Note: if n is primal, x will always be n no matter the value of n_conf
–>
XV/ Internal representations & data structures
SQL & RDD:
join are materialized as ZippedPartitionsRDD2 whose memory format depends on the provided var f: (Iterator[A], Iterator[B]) => Iterator[V]
narrow transformations are materialized as MapPartitionsRDD, whose memory format depends on the provided f: (TaskContext, Int, Iterator[T]) => Iterator[U] // (TaskContext, partition index, iterator)
both have a class attribute preservesPartitioning tagging: “ Whether the input function preserves the partitioner, which should be false unless prev [previous RDD] is a pair RDD and the input function doesn’t modify the keys.”
Unions results in a UnionRDD, big picture: Each virtual partition is a list of parent partitions.
A repartition by key called on a UnionRDD where all the parents are already hashpartitioned will only trigger a coalesce partitioning.
edges.repartition(5).union(edges.repartition(3)).mapPartitions(p => Iterator(p.size)).show()
+-------+
| value|
+-------+
| 877438|
| 874330|
| 888988|
| 883017|
| 873434|
|1424375|
|1500710|
|1472122|
+-------+
With RDDs, better to use sc.union instead of chaining unions. In SQL it’s automatically optimized.
SQL: INSERT Tungsten UnsafeRow binary format
WholestageCodegen.doExecute (overriding of SparkPlan.doExecute) mapPartitions of parent RDD associating to them a Iterator[InternalRow] based on a generated class extending BufferedRowIterator (named GeneratedIteratorForCodegenStageX) which fill a LinkedList[InternalRow] (append method inputing a written UnsafeRowWriter’s getRow output)
RDD[UnsafeRow] partitions are sometimes materialized as contiguous byte arrays, CPUs cache hit-ration effective on iteration:
Datasets’collect(which is used by broadcast thread on driver among others) usescollectFromPlanwhich usesSparkPlan.executeCollectwhich usesSparkPlan.getByteArrayRdd: RDD[(Long, Array[Byte])]: “ Packing the UnsafeRows into byte array for faster serialization. The byte arrays are in the following format: [size] [bytes of UnsafeRow] [size] [bytes of UnsafeRow] …”. RDDs does not. On this space optimized RDD it calls RDDs’ concat:def collect(): Array[T] = withScope { val results = sc.runJob(this, (iter: Iterator[T]) => iter.toArray) Array.concat(results: _*) }
Note: the toArray is free because after getByteArrayRdd, the partition is an iterator of only one element which is a tuple (number_of_rows, optimized_byte_array).
- Hash joins are relying on
BytesToBytesMap, “An append-only hash map where keys and values are contiguous regions of bytes.”
1) Join
2) Join algorithms families
- Nested loop: For each row in table A, loop on table B’s rows to find matches
$O(\vert edges \vert . \vert vertices \vert)$
for e in edges: for v in vertices: if join_condition(e, v): yield e + v - Hash join: Create a join_key -> row hashmap for the smallest table. Loop on the biggest table and search for matches in the hashmap. $O(\vert vertices \vert + \vert edges \vert)$, only equi joins, additional $O(\vert vertices \vert)$ space complexity
vertices_map = {v.join_key: v for v in vertices} # O($\vert vertices \vert$)
for e in edges: # O($\vert edges \vert$)
v = vertices_map.get(e.join_key, None) # considered O(1)
if v is not None:
yield e + v
- Sort-merge join: Sort tables and iterate on both of them in the same move in one loop
$O(\vert vertices \vert .log(\vert vertices \vert) + \vert edges \vert .log(\vert edges \vert))$ , adaptable to handle not only equi joins
vertices.sort(lambda v: v.join_key) # O($\vert vertices \vert$*log($\vert vertices \vert$)
edges.sort(lambda e: e.join_key) # O($\vert edges \vert$*log($\vert edges \vert$)
i, j = 0, 0
while(i < len(vertices) and j < len(edges)): # O($\vert vertices \vert$ + $\vert edges \vert$)
if vertices[i].join_key < edges[i].join_key and i < len(vertices):
i += 1
elif vertices[i].join_key == edges[i].join_key:
yield vertices[i] + edges[i]
i += 1
j += 1
else:
j += 1
a) Joins in Spark (SQL)
https://github.com/vaquarkhan/Apache-Kafka-poc-and-notes/wiki/Apache-Spark-Join-guidelines-and-Performance-tuning https://databricks.com/session/optimizing-apache-spark-sql-joins
Following DAGs are extracts from Jacek Laskowski’s Internals of Apache Spark)
Main types:
- Broadcasts: base paper: “cost-based optimization is only used to select join algorithms: for relations that are known to be small, Spark SQL uses a broadcast join, using a peer-to-peer broadcast facility available in Spark. (Table sizes are estimated if the table is cached in memory or comes from an external file, or if it is the result of a subquery with a LIMIT)”
(see
org.apache.spark.sql.execution.exchange.BroadcastExchangeExec)RDD[InternalRows]iscollected onto the driver node as anArray[(Long, Array[Byte]]. Can cause this message though: “Not enough memory to build and broadcast the table to all worker nodes. As a workaround, you can either disable broadcast by settingspark.sql.autoBroadcastJoinThresholdto -1 or increase the spark driver memory by setting spark.driver.memory to a higher value”.- It is transformed by the
BroadcastModein use - The partitions resulting data structures are then send to all the other partitions.
- Shuffle: Exchange tasks based on HashPartitioner (
:- Exchange hashpartitioning(id#37, 200))
Implems:
- BroadcastHashJoin: Only if one table is tiny, avoid shuffling the big table
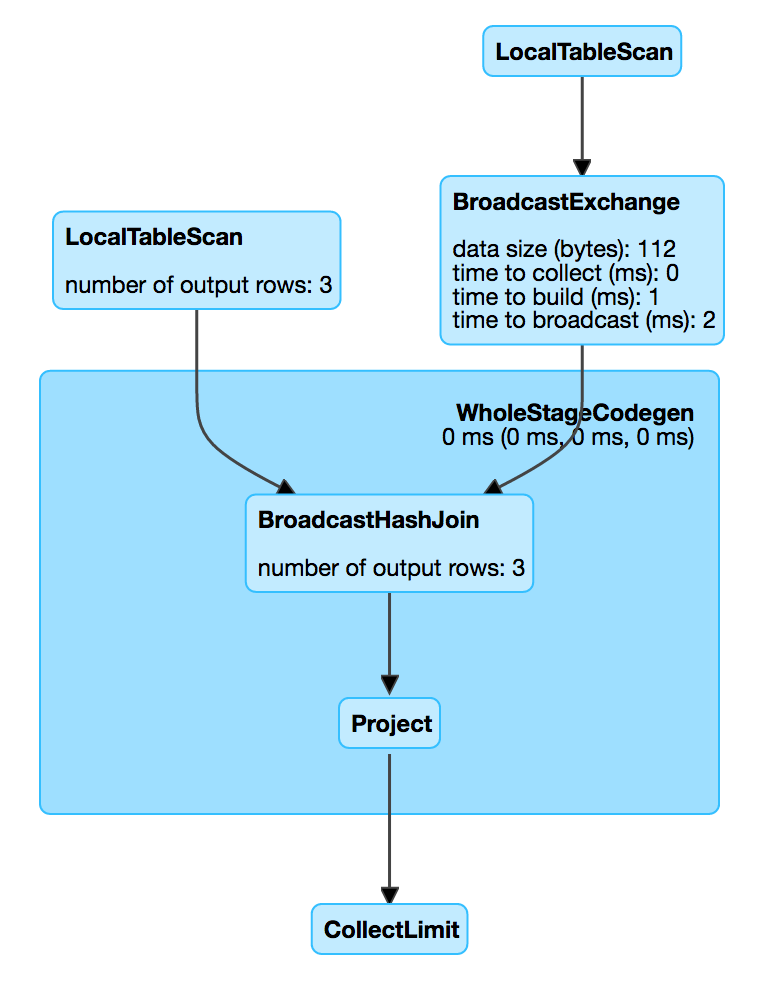
uses +- BroadcastExchange HashedRelationBroadcastMode : build a HashedRelation ready to be broadcasted
spark.sql.autoBroadcastJoinThreshold
“Maximum size (in bytes) for a table that will be broadcast to all worker nodes when performing a join.”
Default: 10L * 1024 * 1024 (10M)
The size of a dataframe is deduced from the sizeInBytes of the LogicalPlan’s Statistics
- ShuffledHashJoin: Only if one is enough small to handle partitioned hashmap creation overhead
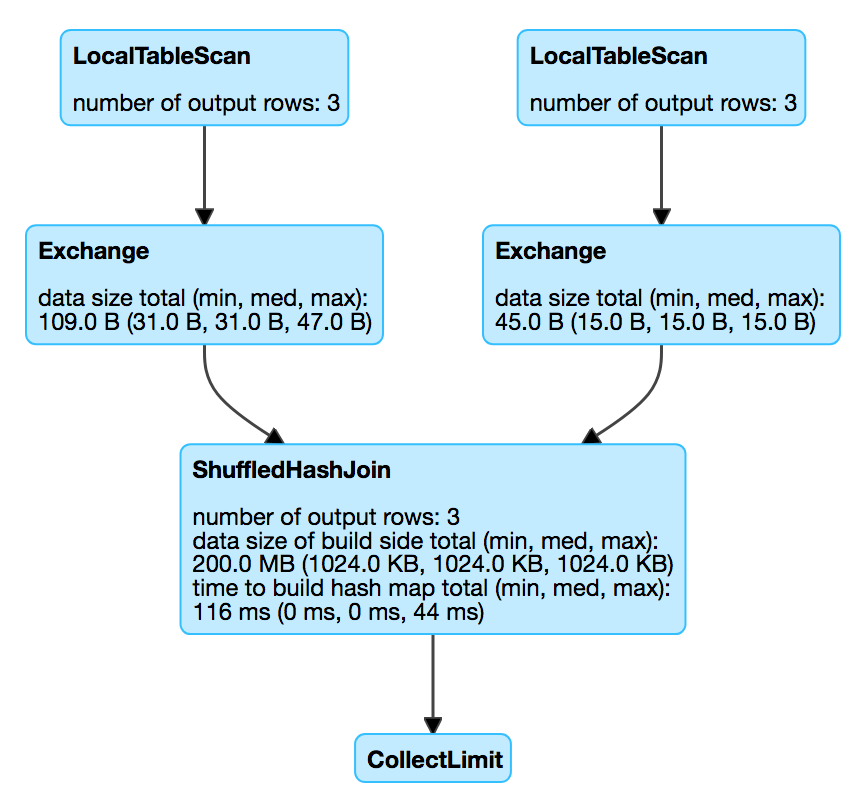
spark.conf.get("spark.sql.join.preferSortMergeJoin")
uses +- Exchange hashpartitioning
in each partition a HashedRelation is build (relies on BytesToBytesMap).
- SortMergeJoin: Fits for 2 even table big sizes, require keys to be orderable
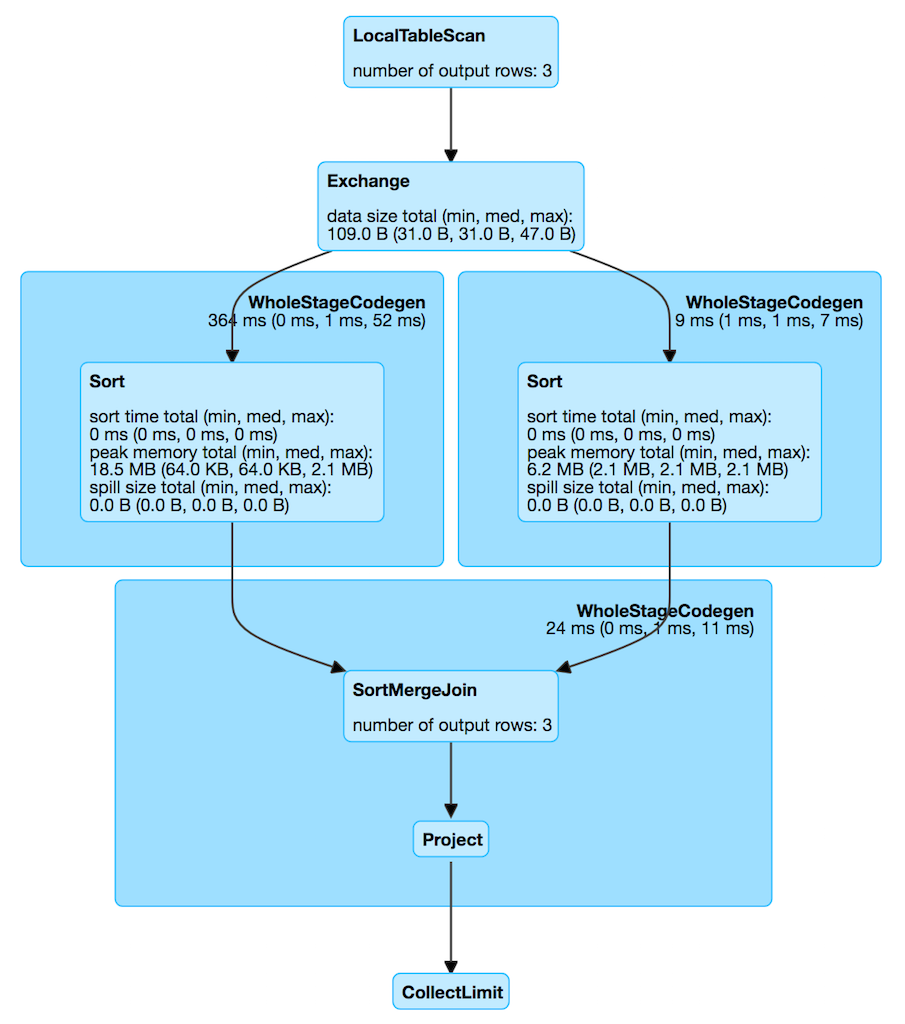
uses +- Exchange hashpartitioning
- BroadcastNestedLoopJoin: Only if one table is tiny, and it’s not possible to use hashing based BroadcastHashJoin (because key is array which is hashed by address, …)

uses +- BroadcastExchange IdentityBroadcastMode pass the partitions as they are: optimized array of UnsafeRows’ bytes obtained with getByteArrayRdd().collect()
spark.sql.join.preferSortMergeJoin is an internal configuration property and is enabled by default.
That means that JoinSelection execution planning strategy (and so Spark Planner) prefers sort merge join over shuffled hash join.
b) Deal with skewed data (SQL & Core)
When loaded, data is evenly partitioned by default. The danger comes when queries involves HashPartioner.
val df = spark.read
.format("csv")
.option("delimiter", ",")
.load("/home/enzo/Data/celineeng.edges")
.toDF("src", "dst", "origin")
df.show(false)
val partitionSizes = df.repartition(1000, col("dst")).mapPartitions(p => Iterator(p.size)).collect()
println(partitionSizes.max, partitionSizes.min, partitionSizes.size) // (36291,116,1000)
i) Use case: web hypertexts links dataset
We almost always have websites with:
- $n°pages » n°partitions$: hashes will fill the full integer range $[0, n°Partition[$
- $n°linksByPage$ is evenly distributed (value =~ 200): no risk that a few partitions containing the most outlinking pages causes a skewing.
- $avg(n°linksByPage) « n°pages$: this is another condition for reduction of the the variance of the size of partitions (if it was not the case, hash partitioning can be skewed).
The following query won’t cause skew problems, partition receiving quite evenly $\vert edges\vert$/n°partitions records each,
SELECT * FROM edges JOIN vertices ON edges.src = vertices.id
But, as every page points back to the home, the hash partitioning on edges.dst may lead to a big skewing: the partition containing the home key will at least contains $\vert vertices \vert$ records.
SELECT * FROM edges JOIN vertices ON edges.dst = vertices.id
Formalization of the skew problem in the context of a link dataset:
We have a skew problem $\iff\vert vertices \vert » avg(n°recordByPartition)$
$\iff \vert vertices \vert » \frac{\vert edges \vert}{n°partitions}$
$\iff n°partitions » \frac{\vert edges \vert}{\vert vertices \vert}$
$\iff n°partitions » avg(n°linksByPage)$
WHY try to reduce skewing ? Because:
- A partition being processed only by one task at a time, the few tasks assigned to process the huge partitions will delay the end of the step. They will make the majority of the cores just wait for long skewed tasks to end.
- Skew limits to the horizontal scaling potential: It is useless to make smaller partition and get more cluster cores because the huge skewed partitions will not be cut and horizontal scaling will just lead to more cores wasting.
c) Fighting skew: presentation of some workarounds
i) Convert to Broadcast join
If the skewed big table is joined with a relatively, try to repartition evenly (RoundRobinPartitioning, repartition(n)) and use a broadcast join if spark does not managed to do it itself (tune threshold "spark.sql.autoBroadcastJoinThreshold" to the desired size in Bytes.
ii) The 2-steps join
Trick: (<hubs> = (home_id) but can contains other hubs)
SELECT *
FROM edges JOIN vertices ON edges.dst = vertices.id
WHERE edges.dst NOT IN (<hubs>);
val hashJoin = edges
.join(
vertices,
edges("dst") === vertices("id")
)
.where(not(edges("dst").isin(<hubs>)))
So second query will be converted to a broadcast join (=replicated join=Map-side join):
SELECT *
FROM edges JOIN vertices ON edges.dst = vertices.id
WHERE edges.dst IN (<hubs>);
val broadcastJoin = edges
.join(
broadcast(vertices),
edges("dst") === vertices("id")
)
.where(edges("dst").isin(<hubs>))
The partial results of the two queries can then be merged to get the final results.
val df = hashJoin.union(broadcastJoin) // by position
val df = hashJoin.unionByName(broadcastJoin) // by name
iii) 3) Duplicating little table
implem here for RDDs: https://github.com/tresata/spark-skewjoin
iv) fighting the “nulls skew”
- dispatching https://stackoverflow.com/a/43394695/6580080 Skew may happen when key column contains many null values. Null values in key column are not participating in the join, but still, as they are needed in output for outer joins, they are hashpartitioned as the other key and we end up with a huge partition of null key:
- minor?: This slow down the join (sorting, many nulls to skip)
- major: this forces one task to fetch many record over network to build the partition.
Fix:
df.withColumn("key", expr("ifnull(key, int(-round(rand()*100000)))"))
(simplified in the case there is no key < 0)
- filter:
val data = ...
val notJoinable = data.filter('keyToJoin.isNull)
val joinable = data.filter('keyToJoin.isNotNull)
joinable.join(...) union notJoinable
d) multi-join prepartitioning trick @ LinkedIn
TODO https://fr.slideshare.net/databricks/improving-spark-sql-at-linkedin TODO: Matrix multiplicityhttps://engineering.linkedin.com/blog/2017/06/managing–exploding–big-data
3) TODO: Range Joins
TODO
4) GroupBy (SQL & Core)
For groupBy on edges.dst, all’s right because only the pre-aggregates (partial_count(1), 1 row per distinct page id in each partition) are exchanged through cluster: This is equivalent to the rdd.reduce, rdd.reduceByKey, rdd.aggregateByKey, combineByKey and not like rdd.groupByKey or rdd.groupBy which does not perform pre-aggregation and send everything over the network…
SELECT src, count(*) FROM edges GROUP BY src
== Physical Plan ==
*(2) HashAggregate(keys=[src#4L], functions=[count(1)])
+- Exchange hashpartitioning(src#4L, 48)
+- *(1) HashAggregate(keys=[src#4L], functions=[partial_count(1)])
+- *(1) InMemoryTableScan [src#4L]
(* means WholeStageCodegen used)
5) Sort (SQL & Core)
An orderBy starts with a step of exchange relying on RangePartitioner that “partitions sortable records by range into roughly equal ranges. The ranges are determined by sampling the content of the RDD passed in.” (scaladoc)
This might not cause skew because the algorithm is based on a sampling of partitions that gives an insight on the distribution of the keys in the entire RDD, BUT if there is a specific value of the key that is very very frequent, its weight will not be divided and we will have one partition quite big containing only this skewed key.
See RangePartitioner.sketch (determines smooth weighted boundaries candidates) and RangePartitioner.determineBounds (determine boundaries from candidates based on wanted partitions, …)
The result of sort step is sorted partitions that does not overlap.
SELECT src, count(*) as c FROM edges GROUP BY src ORDER BY c
== Physical Plan ==
*(3) Sort [c#18L DESC NULLS LAST], true, 0
+- Exchange rangepartitioning(c#18L DESC NULLS LAST, 48)
+- *(2) HashAggregate(keys=[src#4L], functions=[count(1)])
+- Exchange hashpartitioning(src#4L, 48)
+- *(1) HashAggregate(keys=[src#4L], functions=[partial_count(1)])
+- *(1) InMemoryTableScan [src#4L]
6) Exchange/Shuffle (SQL & Core)
-
http://hydronitrogen.com/apache-spark-shuffles-explained-in-depth.html
-
Shuffle strategies: https://0x0fff.com/spark-architecture-shuffle/
-
related issues: SPARK-2044 SPARK-3376 SPARK-4550
Shuffle execution:
- local partitions map output are packed in execution memory region and spilled to local file system by batch when memory become saturated
- outputs targeting the same partition are spilled to an unique file
- Shuffle output files consist of the stage output serialized objects
- Shuffle output files are compressed using the algorithm set in
spark.io.compression.codec(default using lz4). (source: https://stackoverflow.com/a/40151577/6580080)
(source: https://stackoverflow.com/a/40151577/6580080) - Shuffle spilled files that targets the same partition are merged within each executor. This merge phase is avoided if manipulated partitions do fit entirely in memory and a single file can be written, without need for temporary spillings.
- when a file corresponding to a given partition id has been written completely on map side, the shuffle manager states that the chunk is ready to be fetched by reduce side tasks.
a) Actors involved in shuffle (FIXME)
-
ShuffleManageris trait that is instantiated on driver (register shuffles) and executors (ask to write or read data over connections with other executors). The default current implementation isSortShuffleManager. Note: Memory-based shuffle managers proposed with first graphx release has been abandoned because it lacks in reliability and do not gain much in speed because disk based shuffles leverage hyper fast data transfers withjava.nio.channels.FileChannel.transferTo(...). SSDs storage usage adds also a great speed up. -
The
ShuffleManager.getReader: ShuffleReaderallows to fetchorg.apache.spark.sql.execution.ShuffledRowRDD extends RDD[InternalRow]which “is a specialized version oforg.apache.spark.rdd.ShuffledRDDthat is optimized for shuffling rows instead of Java key-value pairs”. SeeBypassMergeSortShuffleWriterwhich relies onDiskBlockObjectWriter&BlockManager -
an
ExternalShuffleServiceis a server that serves the map output files to guarantee their availability in case of executor failure, by not making executors directly serve each others.
b) Spark UI Shuffle insights
- the size under shuffle write and shuffle read sections are values after compression.
c) Exchange-optimized jobs
Shuffle can be the bottleneck step for I/O bound jobs. Writing exchange-optimized jobs it is not about reducing the number of shuffle steps but about reducing the total amount of data passed over the network during the job.
For example, Aaron Davidson presents an optimization in its talk (A Deeper Understanding of Spark Internals), for a job counting distinct names per initial letter:
val names: RDD[String] = ...
names
.map(name => (name.charAt(0), name))
// shuffle (one character, name) pairs for ALL names
.groupByKey()
.mapValues(names => names.toSet.size)
is functionally equivalent but slower than:
val names: RDD[String] = ...
names
// shuffle names, with a pre-aggregation
.distinct()
.map(name => (name.charAt(0), 1))
// light shuffle of (one character, 1) pairs, pre-aggregated
.reduceByKey(_ + _)
- While it adds an additional shuffle it still reduces the total amount of shuffled data, making the job faster.
7) Exchanges planning (SQL)
Exchange are carefully optimized by Catalyst and are ordered to be as cheap as possible.
For example:
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", 1)
val sch = StructType(Seq(StructField("id", LongType), StructField("v", LongType)))
val df1: DataFrame = spark.read.schema(sch).load(...)
val df2: DataFrame = spark.read.schema(sch).load(...)
df1.join(df2.repartition(col("id")).groupBy("id").count(), df1("id") === df2("id")).explain()
*(5) SortMergeJoin [id#0L], [id#4L], Inner
:- *(2) Sort [id#0L ASC NULLS FIRST], false, 0
: +- Exchange hashpartitioning(id#0L, 200)
: +- *(1) Project [id#0L, v#1L]
: +- *(1) Filter isnotnull(id#0L)
: +- *(1) FileScan parquet [id#0L,v#1L] ...
+- *(4) Sort [id#4L ASC NULLS FIRST], false, 0
+- *(4) HashAggregate(keys=[id#4L], functions=[count(1)])
+- *(4) HashAggregate(keys=[id#4L], functions=[partial_count(1)])
+- Exchange hashpartitioning(id#4L, 200)
+- *(3) Project [id#4L]
+- *(3) Filter isnotnull(id#4L)
+- *(3) FileScan parquet [id#4L] ...
/!\ Unecessary exchange is triggered when renaming columns:
edges.repartition(10, col("src")).groupBy("src").count().explain()
edges.repartition(10, col("src")).withColumnRenamed("src", "id").groupBy("id").count().explain()
== Physical Plan ==
*(2) HashAggregate(keys=[src#98L], functions=[count(1)])
+- *(2) HashAggregate(keys=[src#98L], functions=[partial_count(1)])
+- Exchange hashpartitioning(src#98L, 10)
+- *(1) FileScan csv [src#98L] ...
== Physical Plan ==
*(3) HashAggregate(keys=[id#115L], functions=[count(1)])
+- Exchange hashpartitioning(id#115L, 48)
+- *(2) HashAggregate(keys=[id#115L], functions=[partial_count(1)])
+- *(2) Project [src#98L AS id#115L]
+- Exchange hashpartitioning(src#98L, 10)
+- *(1) FileScan csv [src#98L] ...
XVI/ The OOM Zone
Spark may be able to deal with any size of input data, even with one having poor partitioning with sizes completely exceeding the execution memory of your executors: It is an “in-memory as possible” engine that tries to work in memory but when it becomes impossible it spills data to disk. This is the theory, but in practice you will face evil OOMs (OutOfMemoryErrors): This is because Spark’s data are not just RDDs: There are many **auxiliary data structures in memory ** that are used by Spark and that may grow with partitions sizes, potentially leading to OOMs.
An Intel’s article about AE says about number of partitions: “If it is too small, then lower parallelism, and each reduce task has to process more data. Spilling to disk even happens as memory may not hold all data. In the worst case, it may cause serious GC problems or OOMs.”
1) “all is right” scenarios
If no complex operators like sort are involved, a simple range followed by a repartitioning manipulating all along a single partition of more than 10GB with an executor memory of 1GB will work just fine:
val spark = SparkSession.builder
.config("spark.executor.memory", "1g")
.config("spark.driver.memory", "512m")
.master("local[1]")
.appName("testLargePartition")
.getOrCreate()
val df = spark.range(0, 100000000, 1, 1)
.withColumn("some_string", lit("a"*100))
.repartition(1)
df.explain()
/*
Exchange RoundRobinPartitioning(1)
+- *(1) Project [id#0L, aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa AS some_string#2]
+- *(1) Range (0, 100000000, step=1, splits=1) */
df.write.csv("/home/enzo/Data/11GB.csv")
2) When OOMs are of the party
TODO: Complete me
java.lang.OutOfMemoryError: GC overhead limit exceeded
- Fixable by:
refs:
XVII/ Other gotchas
|error|reason|workaround|
|–|–|–|
|Kryo serialization failed: Buffer overflow. Available: <available>, required: <required>. To avoid this, increase spark.kryoserializer.buffer.max value.| The biggest object that has to be kryo-serialized is bigger than spark.kryoserializer.buffer.max. This can be a large record or a large object that has to be broadcasted (even if you do not explicitly broadcast any object, a catalyst optimization may make a join be executed using a Broadcast Exchange)|Increase spark.kryoserializer.buffer.max (up to 2048m) or broadcast smaller objects or desactivate auto broadcast optimization by setting spark.sql.autoBroadcastJoinThreshold to -1.|
|YARN container killed with exit code 143|memory/GC issue|Same workaround as OOMs|
Other reading:*
- https://community.cloudera.com/t5/Support-Questions/How-to-process-a-large-data-set-with-Spark/m-p/39428
How to simulate an executor’s crash, deterministically
It may be useful in order to see if the app recovers its state cleanly after executor failures at some given precise points in the spark App.
The first attempt of the job triggered by the following line will crash the executor that contains the first partition of someRDD:
someRDD.mapPartitionsWithIndex {
case (id, partition) => {
if (id == 0 && TaskContext.get().attemptNumber() == 0) System.exit(0)
Iterator()
}
}
XVIII/ Configuration
There is 3 ways to pass a configuration property to an spark application’s SparkSession. Here is the order of priority from the highest to the lowest:
- Properties set directly on the SparkConf object in app code creating the
SparkSession. - Flags passed to spark-submit or spark-shell
- Options in the spark-defaults.conf file
Note: Deprecated configuration keys never take precedence over their substitute, whatever how they are passed.
Properties set directly on the SparkConf take highest precedence, then flags passed to
spark-submitorspark-shell, then options in thespark-defaults.conffile
Useful conf
spark.hadoop.mapred.output.compress=falseavoid output files to go through a default.snappycompression when written (or override the default codec usingspark.hadoop.mapred.output.compression.codec).
XIX/ Coming soon
1) ouverture: Adaptative Execution (AE) in 3.0.0
apache/spark master branch is about to be released in the next months as Spark 3.0.0. AE open since 1.6 has been merged 15/Jun/19. (Lead by # Carson Wang from Intel)
a. dynamic parallelism
I believe Carson Wang is working on it. He will create a new ticket when the PR is ready.
b. sort merge join to broadcast hash join or shuffle hash join
It’s included in the current framework
c. skew handling.
I don’t think this one is started. The design doc is not out yet.
B/ Powerful external projects
- Uppon Spark ML:
- JohnSnowLabs/spark-nlp: Natural language processing complete toolbox from lemmatization and POS tagging to BERT embedding.
- salesforce/TransmogrifAI: Auto ML (no Deep Learning) integrating following algorithms under the hood:
- classification ->
GBTCLassifier,LinearSVC,LogisticRegression,DecisionTrees,RandomForestandNaiveBayes - regression ->
GeneralizedLinearRegression,LinearRegression,DecisionTrees,RandomForestandGBTreeRegressor
- classification ->
C/ References
- 2011 Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing, Zaharia Chowdhury Das Dave Ma McCauley Franklin Shenker Stoica
- 2013 GraphX: A Resilient Distributed Graph System on Spark, Reynold S Xin Joseph E Gonzalez Michael J Franklin Ion Stoica
- 2013 Shark: SQL and Rich Analytics at Scale, Reynold S. Xin, Josh Rosen, Matei Zaharia Michael J. Franklin Scott Shenker Ion Stoica
- 2014 GraphX: Graph Processing in a Distributed Dataflow Framework, J E. Gonzalez R S. Xin A Dave, D Crankshaw M J. Franklin I Stoica
- 2015 Spark SQL: Relational Data Processing in Spark, Michael Armbrust Reynold S. Xin
- spark/graphx and graphframes sources
- Spark SQL paper
- GraphX 2013/2014 papers
- Map-side join in Hive
- Skewed dataset join in Spark
- Mastering Spark SQL
- Partitioning with Spark GraphFrames
- Big Data analysis Coursera
- HashPartitioner explained
- Spark’s configuration (latest)