3. Presented solution: flexible-memoization
Thanks to the previous section we gained a good understanding of all the key concepts and major issues regarding our goal. All the approaches investigated helped me to design the solution about to be presented, which I named flexible-memoization.
Among all the approaches discussed I have chosen memoization because its realization may profit not only to the use case specific to our problematic’s use case. I will in this last part introduce flexible-memoization’s key features, API and design. We will end this work by showing how to use it to seamlessly reuse expensive UDFs results in Spark SQL jobs, thus solving the problematic of this master’s thesis.
3.1. Goals definition
Through the analysis of the state-of-the-art, I defined the following goals for my memoization solution:
- Be simple to use and to extend.
- Handle any function.
- Provide a clear range of built-in cache management options fetching the majority of the needs.
- Treat objects equality by value and content as much as possible.
3.2. Usage overview
This section will briefly explain how one can use flexible-memoization.
3.2.1. Install
Flexible-memoization is packaged as a GitHub Maven package. You can use it through the following dependency in your pom.xml:
<project ...>
...
<dependencies>
...
<dependency>
<groupId>com.bonnalenzo</groupId>
<artifactId>flexible-memoization</artifactId>
<version>1.0.3-ignite2.7.5-s_2.11</version>
</dependency>
...
</dependencies>
...
<repositories>
...
<repository>
<id>github-ebonnal</id>
<url>https://maven.pkg.github.com/ebonnal/flexible-memoization</url>
</repository>
</repositories>
...
</project>
And in your /path/to/.m2/settings.xml
<settings xmlns="http://maven.apache.org/SETTINGS/1.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/xsd/settings-1.0.0.xsd">
...
<servers>
...
<server>
<id>github-ebonnal</id>
<username>YOUR_GITHUB_USERNAME</username>
<password>YOUR_GITHUB_TOKEN</password>
</server>
</servers>
</settings>
Check out the documentation about installing a GitHub Maven package.
3.2.2. Hello example
1) Import Memo class
import com.bonnalenzo.flexiblememoization.memo.impl.Memo
2) Create your memoizer
val memo: Memoizer = new Memo()
3) Memoize any Scala function you want to
val memoHello = memo((name: String) => s"Hello $name !")
4) Use the memoized function
println(memoHello("Enzo"))
3.2.3. Recursive examples
Here are some classic examples computing Fibonacci series (not optimal $O(n)$ implementation) and factorial, using our memo instance previously created:
lazy val memoFibo: Int => Int =
memo({
case 0 | 1 => 1
case n: Int => memoFibo(n - 1) + memoFibo(n - 2)
}) lazy val memoFacto: Int => Int =
memo({
case 0 | 1 => 1
case n: Int => n*memoFacto(n - 1)
})
The trick is to leverage Scala’s lazy value declarations.
3.3. Structure
3.3.1. UML
Flexible-memoization follows mainly the Object Oriented Programming principles, nevertheless it also tries not to break too many Functional Programming principles.
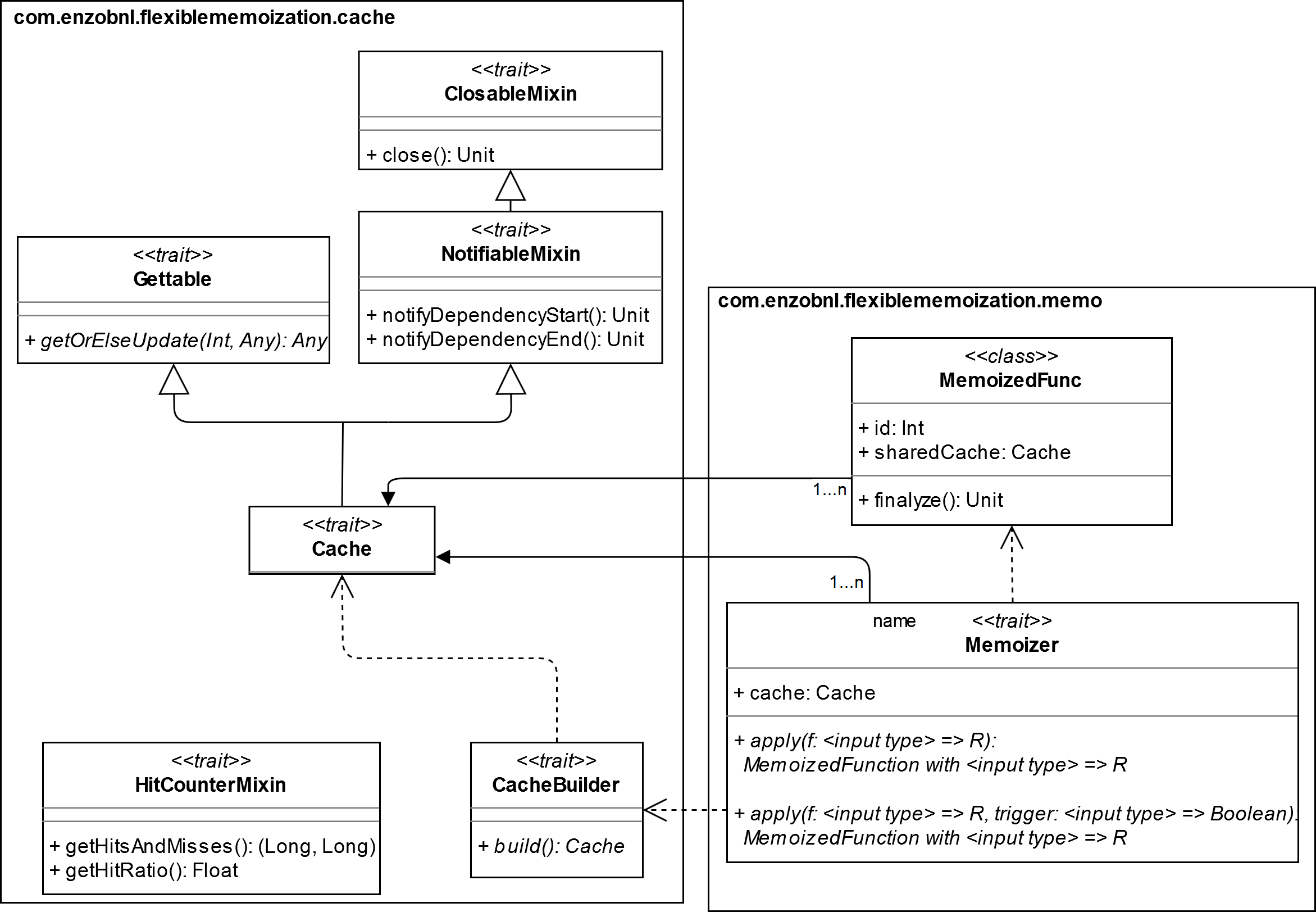
As a support for the following explanations, here is a UML diagram summarizing the relations between flexible-memoization’s abstractions:
3.3.2. Core abstractions
Flexible-memoization core abstractions intend to:
- Guarantee a memoization interface as simple and exhaustive as possible allowing users to memoize any function with minimal effort
- Expose segregated interfaces easy to override, especially for custom caches integration.
Note: In Scala the abstractions are defined as traits. One can view traits as an equivalent for both Java interfaces and abstract classes. A mixin is a trait containing concrete features used to add behaviors to a class inheriting it.
3.3.2.1. Cache sub-package
The cache package defines abstractions related to cache structure. It is independent from any memoization concern.
Gettable
Gettable trait defines the interface for the most central feature of a cache, the retrieving and insertion of key-value pairs.
It only forces its sub-classes to implement one method getOrElseUpdate(key: Int, value: => Any): Any. This method takes an integer as a key and a value of any type. Note that the arrow in value: => Any means that the value argument is lazy, so that the code passed as value will only be run in case it is needed, i.e. when key is missing in the cache.
NotifiableMixin
A object mixing NotifiableMixin earns the ability to be notified when another object starts to depend on it and when this dependency ends. It is an observer in the Observer Pattern, that listens on its notifyDependencyStart and its notifyDependencyEnd methods.
NotifiableMixin extends ClosableMixin. It also keeps a counter of the number of objects depending on him. When this counter pass from 1 to 0, it calls its ClosableMixin’s close method.
Cache
Cache trait defines the minimal features needed to back a Memoizer. It is a Gettable mixing NotifiableMixin.
HitCounterMixin
HitCounterMixin provides methods to update counters of hits and misses, allowing to retrieve them or to compute hit-ratio score.
CacheBuilder
CacheBuilder is a Builder Pattern, forcing the implementation of a build(): Cache method. It provides to the user a simple way to instantiate Caches, hiding potentially complex or confusing details of construction.
3.3.2.2. Memo sub-package
The memo sub-package relies on the cache sub-package and contains sources relative to memoization.
3.3.2.3. Memoizer
Memoizer defines the central interface of the library, the one used to memoize functions.
It enforces the exhaustive handling of any function. It exposes overloaded apply methods. There is 22 of them, one for each possible function arity, from I => R to (I1, I2, I3, ..., I22) => R. Unlike in many other memoization libraries, here the user is not forced to tupleize its multi-arity functions (i.e. to change (I1, I2, ..., In) => R into ((I1, I2, ..., In)) => R).
The apply methods return a function that has the same signature as the original function taken in input. It is in addition decorated with the behaviors of the class MemoizedFunction that is introduced in the next point. This is a form of dynamic Decorator Pattern.
Each one of the 22 apply’s overloadings are doubled with a variant. These alternatives take in input another function that has the same signature as the function being memoized except that it is forced to return a Boolean. This second function will act as a trigger for memoization behavior:
val iLastChars = (i: Int, s: String) =>
s.substring(Math.max(0, s.length - i)) val memoILastChars = new Memo()(
iLastChars, trigger=(i: Int, _: String) => i > 1000
)
The following lines create a memoized function memoILastChars that will only use its underlying cache to store or retrieve values if its i input argument is greater than 1000.
This feature aims at letting user chose to only leverage caching when it worth it.
3.3.2.4. MemoizedFunction
MemoizedFunction class defines behaviors that will decorate memoized functions. It owns an id and a Cache instance.
It is a subject in the Observer Pattern formed with NotifiableMixin: When a MemoizedFunction is created it notifies its Cache attribute and when it is garbage collected, it also informs it. This last notification is done in the finalyze() method that is the method that the garbage collector calls on each object just before it cleans them. This notification system allows caches to close themselves if needed, when no more memoized functions depends on them.
3.3.3. Provided implementation
One can find built-in implementations of previous abstractions, in com.bonnalenzo.flexiblememoization.memo.impl and com.bonnalenzo.flexiblememoization.cache.impl. The next section will introduce them.
3.3.3.1. Memo
Memo is the concrete implementation of the Memoizer trait. We have already encountered it in the usage overview section.
Equality handling
Memo defines how memoized function input will be hashed to become a cache key. Like previously discussed, this is a crucial point that need to be implemented carefully because it directly impact to which extension results will be shared.
This task is delegated to the method getHashCode(args: Any*) owned by Memo’s companion object (Scala design equivalent to the use of a static method). getHashCode(args: Any*) arguments are pattern matched and based on the case, a different hashing policy is applied:
Iterators are hashed using built-in.hashCode(), they are matched first to ensure that automatic iterator-function conversions will not occur.Arrays are casted toSeqs and hashed using built-in.hashCode().- The 22 different function arities are hashed using KeyChain [8], the previously presented tool that hash functions based on their bytecode.
- Every other types are hashed using built-in
.hashCode().
The hashes of all the arguments are then put inside a tuple that is hashed in turn using .hashCode().
A memoized function generates keys for a given set of inputs by calling getHashCode(args: Any*) on their id followed by every input elements. The id being itself generated at the moment of the instantiation using getHashCode, we end up with cache results that are shared between memoized functions that have the same original function’s bytecode.
Underlying Cache
Memo takes as constructor parameter a Cache or CacheBuilder instance at runtime. This convenient Strategy Pattern abstracts Memo behavior from its underlying cache management.
3.3.3.2. Built-in Caches
The library comes with a range of caches whose goal is to fulfill the majority of the needs. It faces the “no free lunch” law by giving flexibility to the user.
Each cache is structured in the same way:
- One or more private classes implemented as Adapter Patterns that makes underlying cache technology comply with the
Cacheinterface. User should never have to deal with them. - A
CacheBuilderthat allows user to easily manipulate the parameters exposed to him and finally to build aCacheinstance. All the builders are functional oriented in the sense that all the builders are immutable and their parameters setting methods always return new builder objects.
Flexible-memoization features three built-in caches:
- Caffeine based one.
- Ignite based one.
- Map based ones: These are non optimized implementations based only on Scala collections. Still it contains an interesting purely computation-cost-based eviction policy.
Caffeine Based
A Caffeine based cache is integrated into flexible-memoization because it is the most used implementation of the WC-W-TinyLFU eviction algorithm that provides state-of-the-art average performances. It is a very versatile choice for the user, addressing small and medium sized workloads.
The CaffeineCacheAdapter implements Cache trait with HitCounterMixin, adapting com.github.blemale.scaffeine.Cache to the Cache interface.
One can instantiate a memoizer backed by a Caffeine cache simply with:
new Memo(new CaffeineCacheBuilder().withMaxEntryNumber(100000))
Note that the adaptability and the little overhead cost of Caffeine based cache makes it a first choice for many needs, thus it has been set to be the default cache for Memo: new Memo() is equivalent to new Memo(new CaffeineCacheBuilder()).
Ignite based
While the Caffeine based cache addresses efficiently small and medium sized workload needs, the Ignite based cache provides the horizontal scaling memoization solution that is our primary goal.
Among Redis, Aerospike and Ehcache, Ignite has been selected because it is the only one matching all our requirements:
- Propose a good set of built-in eviction policies.
- Leverage off-heap memory.
- Having a peer-to-peer cluster mode that allows it to be easily integrated without having to deal with asymmetric global state issues that master-slave or client-server models can introduce.
- Be simple to embed entirely in our Scala library.
- Be completely open-source.
The IgniteCacheAdapter implements Cache trait with HitCounterMixin, adapting org.apache.ignite.IgniteCache to the Cache interface.
This Ignite cache leverages both on-heap and off-heap policies.
One can for example instantiate a memoizer backed by an Ignite cache with an initial off-heap size of 4Gb with:
scala
new Memo(new IgniteCacheBuilder()
.withOffHeapEviction(OffHeapEviction.RANDOM_LRU) .withInitialOffHeapSize(4*1024*1024) .build())
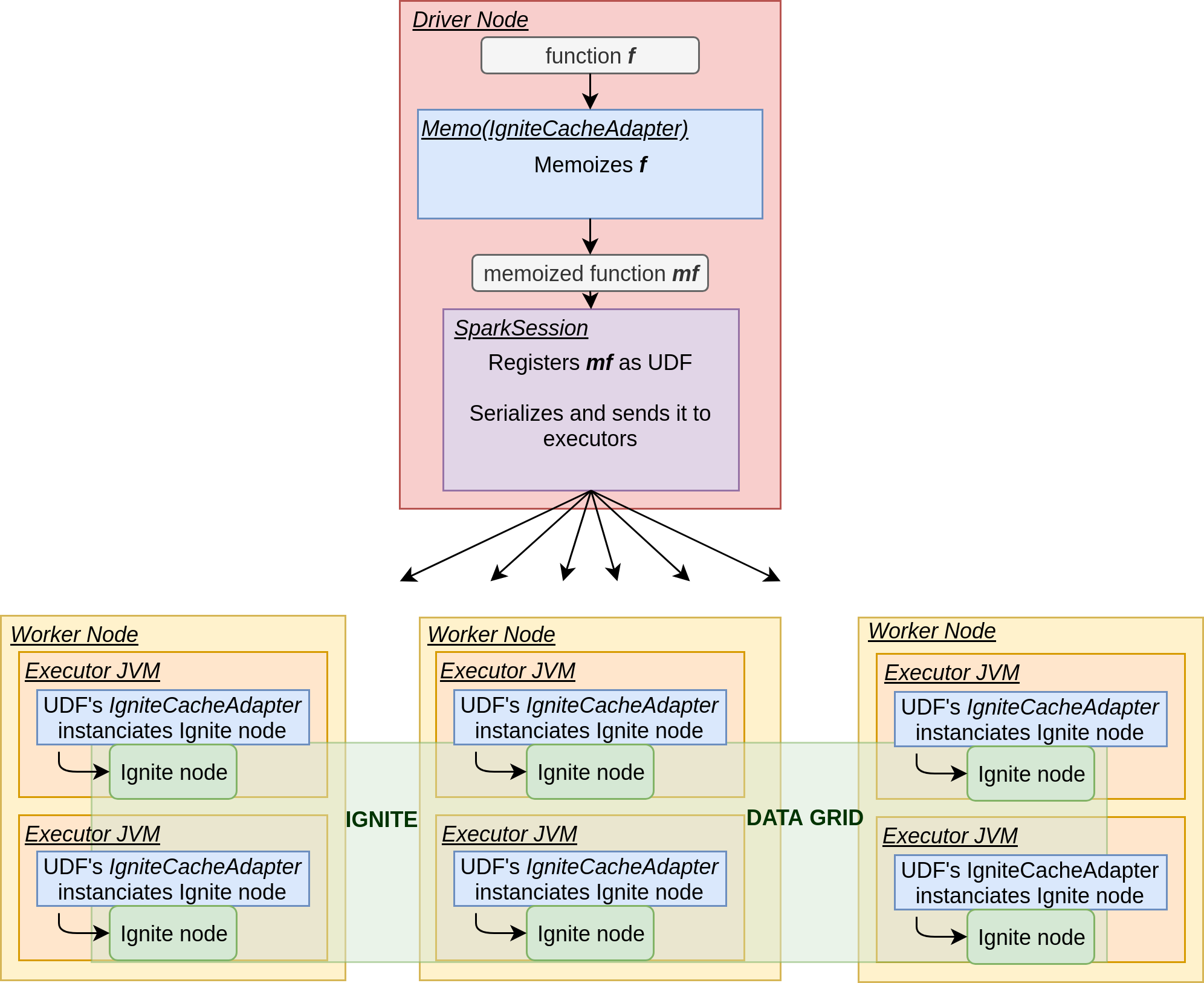
3.4. Answering the problematic
We will finally see how to solve our problematic using flexible-memoization. This will be as quick as the solution is simple.
Given a spark: SparkSession and a registered table “table”, here is a minimalist example:
scala
val f: Int => Int = [...] // some expensive computation
val igniteMemoizer = new Memo(new IgniteCacheBuilder().build())
spark.udf.register("mf", igniteMemoizer(f)) spark.sql("""SELECT col2, sum(mf(col1)), avg(mf(col1)) FROM
global_temp.table GROUP BY col2""")
Here is what happens behind the scene, for a Spark job run in Client Mode: